
1. Collection Framework?
컬렉션 프레임웍이란 데이터군을 저장하는 클래스들을 표준화한 설계를 의미한다. 여기서 프레임웍이란 표준화된 프로그래밍 방식을 의미한다.
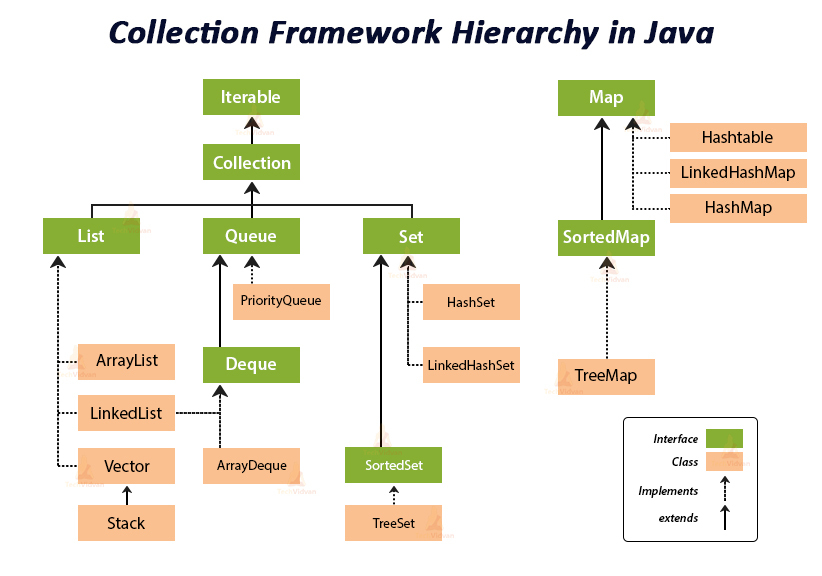
2. 컬렉션 프레임웍의 핵심 인터페이스
컬렉션 프레임웍의 핵심 인터페이스는 세가지가 존재한다.
- List : 순서가 있는 데이터 집합, 데이터 중복을 허용한다 (ArrayList, LinkedList, Vector, Stack)
- Set : 순서가 유지되지 않는 집합, 데이터 중복을 허용하지 않는다.(HashSet, TreeSet)
- Map : 키 - 값 쌍으로 이루어진 데이터 집합. 순서는 유지되지 않으며 키는 중복을 허용하지 않고, 값은 중복을 허용한다
주의할 것은 위 세가지 모두 '인터페이스'라는 것이다. 그리고 여기서 공통점이 많은 List, Set의 공통된 부분을 뽑아 Collection인터페이스를 재정의하였다. Map인터페이스는 공통점이없어 상속계층에도 포함되지 않는다.
3. Collection 인터페이스
List, Set의 조상인 Collection인터페이스에는 아래와 같은 메소드들이 있다.
- boolean add(Object o) : 지정 객체를 Collection에 추가
- void clear() : Collection내 객체를 모두 삭제
- boolean contains(Object o) : 지정된 객체가 컬렉션에 존재하는지 확인
- boolean containsAll(Collection c) : 지정된 컬렉션 내 객체들이 컬렉션에 있는지 확인
- boolean equals(Object o) : 동일한 컬렉션인지 확인
- int hashCode() : 컬렉션의 해시코드 반환
- boolean isEmpty() : 비어있는지 확인
- iterator iterator : 컬렉션의 iterator반환
- boolean remove(Object o) : 객체 o를 삭제
- boolean removeAll(Collection c) : 컬렉션에 포함된 객체를 삭제
- boolean retainAll(Collection c) : 지정된 Collection에 포함된 객체만 남기고 다른 객체들은 Collection에서 삭제한다
- int size() : 컬렉션에 저장된 객체 수 반환
- Object[] toArray() : 저장 객체를 객체배열로 반환
- Object[] toArray(Object[] a) : 지정된 배열에 컬렉션 객체를 저장해 반환
4. List인터페이스
List는 중복을 허용, 저장순서가 유지되는 컬렉션이다.
5. Set인터페이스
중복을 허용하지 않고, 저장순서가 유지되지 않는 컬렉션 클래스를 구현하는데 사용한다.
6. Map인터페이스
Map인터페이스는 키 - 값(Key : Value)를 하나의 쌍으로 묶어 저장하는 클래스이다.
7. Map.Entry인터페이스
Map인터페이스의 내부 인터페이스이다. Key-value쌍을 다루기 위해 내부적으로 구현해 놓았다. 내부 인터페이스인만큼 Map인터페이스를 구현하면 Map.Entry인터페이스도 같이 구현해야한다. 결론적으로 Entry는 (Key-Value)쌍을 의미한다.
- boolean equals(Object o) : 동일한 Entry인지 비교
- Object getKey() : Entry의 key객체를 반환한다
- Object getValue() : Entry의 value객체를 반환한다
- int hashCode() : 해시코드를 반환한다
- Object setValue(Object value) : Entry의 value객체를 지정된 객체(매개변수)로 바꾼다.
8. ArrayList
List인터페이스를 구현한 클래스이다. List를 구현한 만큼 저장순서가 유지되고 중복을 허용한다. 또한 기존에 있던 Vector를 개선한 클래스이다. Object배열을 이용해 데이터를 순차적으로 저장한다. 저장할 공간이 없으면 새로운 배열을 생성해 기존 배열에 저장된 내용을 배열로 복사 후 저장한다(System.arraycopy()원리)
package CollectionFramework;
import java.util.*;
public class testing {
public static void print(List l1, List l2){
System.out.println("List1 : " + l1);
System.out.println("List2 : " + l2);
}
public static void main(String[] args){
// Array List의 디폴트 크기는 10이다. 정수값을 넘겨 초기 크기를 정할 수 있다
ArrayList list1 = new ArrayList(16);
// boolean add(Object o) : ArrayList에 값을 넣는다
list1.add(new Integer(5));
list1.add(new Integer(3));
list1.add(new Integer(1));
list1.add(new Integer(2));
list1.add(new Integer(4));
// ArrayList(Collection c) : 주어진 컬렉션이 저장된 ArrayList생성
// List subList(int start, int end) : start ~ end - 1 index까지의 리스트반환
ArrayList list2 = new ArrayList(list1.subList(1,4));
print(list1,list2);
// Collections클래스 : collection을 활용할 수 있게 해주는 클래스
Collections.sort(list1); // Collections.sort() : 컬렉션을 정렬해준다
Collections.sort(list2);
//boolean containsAll(Collection c) : 컬렉션 c가 해당 컬렉션내 객체가 모두 포함되어있는지 반환
System.out.println("list1.containsAll(list2) : " + list1.containsAll(list2));
//List는 Object를 저장하므로, 모든 타입의 객체 저장 가능
list2.add("B");
list2.add("C");
print(list1,list2);
// add(int index, Object element) : 주어진 위치에 객체를 저장한다. 해당 위치에 이미 요소가 있다면 해당 요소부터 끝까지 한칸씩 뒤로 복사한다.
list2.add(3,"AA");
print(list1,list2);
// boolean retainAll(Collection c) : 지정된 Collection에 포함된 객체만 남기고 다른 객체들은 삭제
// list1에서 list2와 겹치는 부분만 남기고 나머지 삭제
System.out.println("list1.retainAll(list2) : " + list1.retainAll(list2));
print(list1,list2);
}
}ArrayList를 만들때는 여유있게 크기를 지정해 초기화 하는것이 좋다. 물론 공간이 부족하면 확장을 하지만, 배열을 복사하는 방식이므로 시간이 오래거린다.
9. LinkedList
배열은 가장 기본적인 형태의 자료구조로 구조가 간단하고 사용하기 쉽고, 데이터를 읽어오는데 걸리는 시간이 가장 빠르다는 장점이 있다.
- 크기를 변경할 수 없다
- 크기를 변경할 수 없으므로, 새로운 배열을 생성해서 데이터를 복사해야한다.
- 실행속도를 향상 시키기 위해서는 충분히 큰 크기의 배열을 생성해야 하므로 메모리가 낭비된다.
- 비순차적인 데이터의 추가 또는 삭제에 시간이 많이 걸린다.
- 차례대로 데이터를 추가하고 마지막에서부터 데이터를 삭제하는 것은 빠르다.
- 배열의 중간에 데이터를 추가하려면, 빈자리를 만들기 위해 다른 데이터들을 복사해서 이동해야한다.
배열의 단점을 보완하기 위해 링크드 리스트 라는 자료구조가 고안되었다. 링크드 리스트는 불연속적으로 존재하는 데이터를 서로 연결한 형태로 구성되어있다. 기본 링크드 리스트는 이동방향이 단방향이다. 다음 요소에 대한 접근은 쉽지만 이전 요소에 대한 접근은 어렵다 이를 보완한것이 더블링크드 리스트인데, 이는 양방향성으로 이동할 수 있다.
Java Linked List클래스는 더블 링크드 리스트로 구현되어있다. Linked List또한 List인터페이스를 구현했기 때문에 ArrayList와 메소드 종류, 기능은 거의 같다
package CollectionFramework;
import java.util.*;
public class testing {
public static void main(String[] args){
ArrayList al = new ArrayList(200000);
LinkedList ll = new LinkedList();
System.out.println("순차적으로 추가하기");
System.out.println("Array List : " + add1(al));
System.out.println("LinkedList : " + add1(ll));
System.out.println();
System.out.println("중간에 추가하기");
System.out.println("ArrayList : " + add2(al));
System.out.println("LinkedList : " + add2(ll));
System.out.println();
System.out.println("중간에서 삭제하기");
System.out.println("ArrayList : " + remove2(al));
System.out.println("LinkedList : " + remove2(ll));
System.out.println();
System.out.println("순차적으로 삭제하기");
System.out.println("ArrayList : " + remove1(al));
System.out.println("LinkedList : " + remove1(ll));
}
public static long add1(List list){
long start = System.currentTimeMillis();
for(int i = 0 ; i < 1000000;i++){
list.add(i+"");
}
long end = System.currentTimeMillis();
return end - start;
}
public static long add2(List list){
long start = System.currentTimeMillis();
for(int i = 0; i < 10000;i++){
list.add(500,"X"); // index 500번에 "X"라는 값을 계속 추가한다.
}
long end = System.currentTimeMillis();
return end - start;
}
public static long remove1(List list){
long start = System.currentTimeMillis();
for(int i = list.size() - 1; i >= 0; i--){
list.remove(i); // Object remove(int index) : index에 있는 값을 remove한다
}
long end = System.currentTimeMillis();
return end - start;
}
public static long remove2(List list){
long start = System.currentTimeMillis();
for(int i = 0; i < 10000;i++){
list.remove(i);
}
long end = System.currentTimeMillis();
return end - start;
}
}ArrayList와 LinkedList를 비교해본 코드이다.
순차적 추가 / 삭제같은 경우에는 ArrayList가 더 빠르다. 반면 중간 데이터를 추가 / 삭제하는 경우에는 LinkedList가 더 빠르다.
9. Stack과 Queue
Stack과 Queue에 대해 알아보자. 스택은 LIFO, 큐는 FIFO구조이다.스택같은 경우에는 데이터를 추가하고 삭제하는 방식이므로, ArrayList로 구현하는게 맞으며, Stack은 클래스가 구현되어있다. 큐는 ArrayList보다 데이터 추가 / 삭제가 쉬운 LinkedList가 더 효율적이다. Queue는 클래스ㅏ가 구현되어있지 않고, 인터페이스만 구현되어있다. Queue는 Queue를 구현한 클래스중 하나를 선택해 사용해야한다.
Stack의 메소드는 아래와 같은 것들이 있다.
- boolean empty() :Stack이 비어있는지 확인한다
- Object peek() : Stack의 맨 위에 저장된 객체를 반환한다. pop()과 달리 객체를 완전히 꺼내지 않는다.
- Object pop() : Stack의 맨 위에 저장된 객체를 꺼낸다
- Object push(Object item) : 스택에 객체를 저장한다
- int search(Object o) : Stack에서 주어진 객체를 찾아서 그 위치를 반환한다.
package CollectionFramework;
import java.util.*;
public class testing {
public static void main(String[] args){
Stack st = new Stack();
st.push("0");
st.push("1");
st.push("2");
System.out.println("Stack");
while(!st.empty()){
System.out.println(st.pop());
}
}
}Queue의 메소드는 아래와 같은 것들이 있다.
- boolean add(Object o) : 지정된 객체를 Queue에 추가한다
- Object remove() : Queue에서 객체를 꺼내 반환한다. 비어있는 경우 NoSuchElementException발생
- Object element() : 삭제없이 요소를 읽어온다. peek과 달리 Queue가 비어있을때 NoSuchElementException발생
- boolean offer(Object o) : Queue객체를 저장, 성공하면 true 실패하면 false를 반환
- Object poll() : Queue에서 객체를 꺼내서 반환, 비어있으면 null을 반환
- Object peek() : 삭제없이 요소를 읽어온다.Queue가 비어있으면 null을 반환
package CollectionFramework;
import java.util.*;
public class testing {
public static void main(String[] args){
Queue q = new LinkedList();
q.offer("0");
q.offer("1");
q.offer("2");
System.out.println("Queue");
while(!q.isEmpty()){
System.out.println(q.poll());
}
}
}https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/Queue.html
Queue (Java SE 17 & JDK 17)
Type Parameters: E - the type of elements held in this queue All Superinterfaces: Collection , Iterable All Known Subinterfaces: BlockingDeque , BlockingQueue , Deque , TransferQueue All Known Implementing Classes: AbstractQueue, ArrayBlockingQueue, ArrayD
docs.oracle.com
여기를 가면 Queue를 구현한 클래스들이 있다.(All known Implementing Classes)
10. Iterator, ListIterator,Enumeration
Iterator, ListIterator, Enumeration 은 모두 컬렉션에 저장된 요소를 접근하는데 사용되는 인터페이스이다. Enumeration은 Iterator의 구버전이며 , ListIterator는 Iterator의 기능을 향상시킨것이다.
< Iterator >
컬렉션 프레임웍은 저장된 요소들을 읽어오는 방법을 표준화했다. 각 요소에 접근하는 기능을 가진 iterator인터페이스를 정의하고, Collection인터페이스에는 Iterator를 반환하는 iterator()를 정의하고있다. iterator()는 Collection인터페이스에 정의된 메소드이다. 이는 당연하게도 자손 인터페이스인 List,Set에도 정의되어있다. iterator()로 Iterator를 얻은 후 요소를 읽을 수 있다. Iterator의 메소드는 아래와 같은 것들이 있다.
- boolean hasNext() : 읽어올 요소가 남아있는지 확인한다 있으면 true 없으면 false
- Object next() : 다음 요소를 읽어온다.
- void remove() : next()로 읽어온 후 삭제한다. 그렇기 때문에 next() 호출 후 호출해야한다.
아래와 같이 작성하면 코드 재사용성을 늘릴 수 있다.
package CollectionFramework;
import java.util.*;
public class testing {
public static void main(String[] args){
Collection c = new ArrayList();
for(int i = 0; i < 10; i++){
c.add(i + 1);
}
Iterator it = c.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}
ArrayList대신 Collection 타입으로 선언한 이유는 Collection이 List, Set계열 클래스들의 부모 클래스가 되기 때문이다. 그렇기 때문에 ArrayList가 아닌 LinkedList로 선언해도 사용이 가능한 것이다.(업캐스팅되는것이다)
< ListIterator >
ListIterator는 Iterator를 상속받아 기능을 추가한 것으로, 컬렉션의 요소에 접근할 때 Iterator는 단방향으로 이동할 수 있는 반면, ListIterator는 양방향 이동이 가능하다. 단 ListIterator는 List인터페이스를 구현한 컬렉션에서만 사용할 수 있다. ListIterator의 메소드는 아래와 같은 것들이 있다.
- void add(Object o) : 객체를 추가한다
- boolean hasNext() : 읽어올 요소가 남아있는지 확인한다
- boolean hasPrevious() : 읽어올 이전 요소가 있는지 확인한다
- Object next() : 다음 요소를 읽어온다.
- Object previous() : 이전 요소를 읽어온다
- int nextIndex() : 다음요소의 index를 반환한다
- int previousIndex() : 이전 요소의 index를 반환한다.
- void remove() : next혹은 previous로 읽어온 요소를 삭제한다
< Enumeration >
Enumeration은 Iterator의 구버전이라고 생각하면된다. 이전버전과의 호환성을위해 남겨두었으며 Iterator를 사용하는것이 좋다. 메소드는 아래와 같다
- boolean hasMoreElements() : 읽어올 요소가 남아있는지 확인한다. 있으면 true없으면 false를 반환한다 (Iterator의 hasNext)
- Object nextElement() : 다음요소를 읽어온다.(Iterator의 next)
11. HashSet
HashSet은 Set인터페이스 구현 클래스이다. Set인터페이스 특징대로 중복 요소를 저장할 수 없으며, 저장 순서도 유지되지 않는다. 저장순서 유지를 위해서는 LinkedHashSet을 사용해 주어야한다.
package CollectionFramework;
import java.util.*;
public class testing {
public static void main(String[] args){
Object[] objArr = {"1",new Integer(1),"2","2","2","3","3","4","4","4"};
Set set = new HashSet();
for(int i = 0; i < objArr.length; i++){
set.add(objArr[i]);
}
System.out.println(set);
}
}String 1과 Integer 1은 자료형이 다르기때문에 중복값으로 취급되지 않는다.
package CollectionFramework;
import java.util.*;
public class testing {
public static void main(String[] args){
Set set = new HashSet();
// int size() : 객체의 저장된 개수를 반환한다.
for(int i = 0; set.size() < 6;i++){
int num = (int)(Math.random() * 45) + 1;
set.add(new Integer(num));
}
// LinkedList(Collection c) : 컬렉션이 포함된 LinkedList를 반환한다.
List list = new LinkedList(set);
Collections.sort(list);
System.out.println(list);
}
}이번에는 객체를 Set에 넣어본다고 가정하자
package CollectionFramework;
import java.util.*;
class Person1{
String name;
int age;
Person1(String name, int age){
this.name = name;
this.age = age;
}
@Override
public String toString(){
return name + " : " + age;
}
}
public class testing {
public static void main(String[] args){
HashSet set = new HashSet();
set.add("abc");
set.add("abc");
set.add(new Person1("Hoplin",10));
set.add(new Person1("Hoplin",10));
System.out.println(set);
}
}
//Result : [abc, Hoplin : 10, Hoplin : 10]결과를 보면 Person1객체내 값이 겹치지만 중복값으로 인식하지 않는다. 이유는 HashSet같은 경우 새로운 요소 추가 전에 기존에 저장된 요소와 동일한 것인지 판별하기 위해서 equals()와 hashCode()를 호출하기 때문이다. 그렇기 때문에 equals()와 hashCode()를 오버라이딩 해서 구현해 주어야 한다.
package CollectionFramework;
import java.util.*;
class Person1{
String name;
int age;
Person1(String name, int age){
this.name = name;
this.age = age;
}
@Override
public String toString(){
return name + " : " + age;
}
@Override
public int hashCode(){
return (name + age).hashCode();
}
@Override
public boolean equals(Object obj){
if(obj instanceof Person1){
Person1 tmp = (Person1) obj;
return name.equals(tmp.name) && age == tmp.age; //name은 String 자료형이다. String 자료형은 내부적으로 equals와 hashCode는 값이 같은 경우 동일한 값으로 리턴하도록 되어있다.
}
return false;
}
}
public class testing {
public static void main(String[] args){
HashSet set = new HashSet();
set.add("abc");
set.add("abc");
set.add(new Person1("Hoplin",10));
set.add(new Person1("Hoplin",10));
System.out.println(set);
}
}
//Result : [abc, Hoplin : 10]equals는 Person1타입 객체인지 확인 후 name, age를 비교하는 방식으로 hashCode()는 name + age값(String)의 hashCode를 불러오는 방식으로 바꾸었다(String은 hashCode()메소드가 내용이 동일할 시에 같은 값으로 반환하도록 오버라이딩 되어있다). 단 아래 조건들을 만족해야한다
- 여러번 호출해도 동일한 int값을 반환해야한다
- equals메소드를 이용해 true를 얻은 두 객체에 대해 각각 hashCode()를 호출해 얻은 값은 같아야한다.
- equals를 이용해 false를 얻은 경우에는 hashCode()의 값이 같이도 괜찮지만 해싱을 사용하는 컬렉션 성능을 향상시키기 위해서는 다른 int를 반환하는것이 좋다.
12. HashMap과 Hashtable
HashMap은 Hashtable의 업그레이드 버전이다. HashMap은 키와 값을 묶어 하나의 데이터로 지정한다는 특징을 갖는다. 해싱을 사용하기 때문에 많은 양의 데이터를 검색하는데 있어서 뛰어난 성능을 보인다.
HashMap은 Entry라는 내부 클래스를 정의한다. 그리고 다시 Entry타입 배열을 선언한다. HashMap은 키와 값을 각각 Object타입으로 저장한다. 즉, (Object, Object)형태로 저장한다.
키는 저장된 값을 찾는데 이용되기 때문에 컬렉션 내에서 유일한 값이어야한다.
package CollectionFramework;
import java.util.*;
public class testing {
public static void main(String[] args){
HashMap map = new HashMap();
map.put("myID","1234"); // put(Object key, Object value) : Key - Value쌍을 맵에 넣는다
map.put("asdf","1111");
map.put("asdf","1234"); // 키값이 겹치는 경우에는 가장 나중에 들어오는 value의 값이 저장되게 된다
Scanner s = new Scanner(System.in);
while(true){
System.out.println("ID와 PW를 입력하세요.");
System.out.print("ID : ");
String id = s.nextLine().trim();
System.out.print("PW : ");
String pw = s.nextLine().trim();
System.out.println();
//boolean containsKey(Object key) : key값이 맵 내에 존재하는 확인한다.
if(!map.containsKey(id)){
System.out.println("입력하신 ID는 존재하지 않습니다. 다시입력해 주세요");
continue;
}
//Object get(Object key) : 지정된 Key의 값을 반환한다. 못찾으면 null반환
if(!(map.get(id)).equals(pw)){
System.out.println("비밀번호가 일치하지 않습니다. 다시입력해주세요");
}else{
System.out.println("id와 비밀번호가 일치합니다");
break;
}
}
}
}위 예제에서는 중복된 키값이 있기 때문에, 사실상 두개밖에 저장되지 않는다.
package CollectionFramework;
import java.util.*;
public class testing {
public static void main(String[] args){
HashMap map = new HashMap();
map.put("A",new Integer(100));
map.put("B",new Integer(200));
map.put("C",new Integer(300));
map.put("D",new Integer(80));
// Set entrySet() : HashMap에 저장된 키와 값을 엔트리의 형태로 Set에 저장해서 반환한다.
Set set = map.entrySet();
// Set은 iterator를 통해 값을 읽어올 수 있다.
Iterator it = set.iterator();
// Map.Entry : Key-Value를 다루기 위해 Map의 내부 인터페이스이다.
while(it.hasNext()){
Map.Entry e = (Map.Entry)it.next();
System.out.println("이름 : " + e.getKey() + "점수 : " + e.getValue());
}
// Set keySet() : HashMap에 저장된 모든 키가 저장된 Set을 반환한다.
set = map.keySet();
System.out.println("참가자 명단 : " + set);
// Collection values() : HashMap에 저장된 값들을 Collection형태로 반환한다.
Collection values = map.values();
it = values.iterator();
int total = 0;
while(!it.hasNext()){
Integer i = (Integer) it.next();
total += i.intValue();
}
System.out.println("총점 : " + total);
// int size() : map에 저장된 데이터 개수를 반환한다.
System.out.println("평균 : " + map.size());
// Collections.max : Collection에서 가장 큰 값을 반환한다
System.out.println("최고점수 : " + Collections.max(values));
// Collections.min : Collection에서 가장 작은 값을 반환한다
System.out.println("최저점수 : " + Collections.min(values));
}
}이번에는 중첩 HashMap을 사용해서 전화번호부를 만들어보자
package CollectionFramework;
import java.util.*;
public class testing {
static HashMap phoneBook = new HashMap();
public static void main(String[] args){
addPhoneNo("Friend","A","111111");
addPhoneNo("Friend","B","222222");
addPhoneNo("Friend","C","333333");
addPhoneNo("Company","D","777777");
addPhoneNo("Company","E","000000");
addPhoneNo("School","1234567");
printList();
}
static void addPhoneNo(String groupName,String name, String tell){
addGroup(groupName);
// Object get(Object key) : key값에 해당되는 value 값을 반환한다.
HashMap group = (HashMap) phoneBook.get(groupName);
// Object put(Object key, Object value) : map에 Key-Value쌍을 넣는다.
group.put(tell,name);
}
static void addPhoneNo(String name,String tell){
addPhoneNo("기타",name,tell);
}
static void addGroup(String groupName){
// boolean containsKey(Object key) : 키값이 있는지 확인한다.
if(!phoneBook.containsKey(groupName)){
phoneBook.put(groupName,new HashMap());
}
}
static void printList(){
// Map.Entry(Key-Value)타입의 쌍을 Set에 담아 반환
Set set = phoneBook.entrySet();
Iterator it = set.iterator();
while (it.hasNext()){
Map.Entry e = (Map.Entry)it.next();
// Map.Entry / Object getValue() : Entry의 Value값을 반환한다.
Set subset = ((HashMap)e.getValue()).entrySet();
Iterator subIt = subset.iterator();
// Map.Entry / getKey() : 키값 반환 | int size() : 저장된 데이터 개수 반환
System.out.println("* " + e.getKey() + "[" + subset.size() + "]");
while(subIt.hasNext()){
Map.Entry subE = (Map.Entry)subIt.next();
String telNo = (String) subE.getKey();
String name = (String) subE.getValue();
System.out.println(name + " " + telNo);
}
System.out.println();
}
}
}13. Properties
Properties는 HashMap의 구버전인 Hashtable을 상속받아 구현한 것으로 HashTable은 값을 (Object, Objcet)형태로 저장하는 반면 Properties는 (String, String)의 형태로 저장하는 더 단순화된 클래스이다. Properties는 주로 애플리케이션의 환경설정과 관련된 속성을 저장하는데 사용된다(XML, text파일 등). 그리고 데이터를 파일로부터 읽고 쓰는 편리한 기능을 제공한다. Properties 또한 Map인터페이스 구현체이므로 저장순서가 유지되지 않는다.
package CollectionFramework;
import java.util.*;
public class testing {
public static void main(String[] args){
Properties prop = new Properties();
// setProperty(String key, String value) : Key-Value를 저장한다 이미 존재하는 Key인 경우 value로 값이 대체된다.
prop.setProperty("timeout","30");
prop.setProperty("language","kr");
prop.setProperty("size","10");
prop.setProperty("capacity","10");
// Enumeration propertyNames() : Properties의 Key가 담긴 Enumeration을 반환한다.
Enumeration e = prop.propertyNames();
// Enumeration : hasMoreElements() : 불러올 값이 더 있는지 검사한다.
while(e.hasMoreElements()){
// Enumeration : nextElement() : 다음 값을 불러온다
String element = (String)e.nextElement();
// String getProperty(String key) : key에 대한 value값을 반환한다. Properties는 (String,String)이므로 String반환타입으로 되어있다.
System.out.println(element + "=" + prop.getProperty(element));
}
System.out.println();
prop.setProperty("size","20");
System.out.println("size = " + prop.getProperty("size"));
System.out.println("capacity = " + prop.getProperty("capacity","20"));
System.out.println(prop);
// void list(PrintStream out) : 지정된 PrintStream에 저장된 목록을 출력한다.
// System.out : 화면과 연결된 표준출력이다.
prop.list(System.out);
}
}텍스트 파일 변경하기 예제를 작성해보자.
package CollectionFramework;
import java.util.*;
import java.io.*;
public class prpty2 {
public static void main(String[] args){
if(args.length != 1){
System.out.println("USAGE : java prpty2 (filename)");
System.exit(0);
}
Properties prop = new Properties();
String inpFile = args[0];
try{
prop.load(new FileInputStream(inpFile));
}catch (IOException e){ // Properties.load의 예외
System.out.println("지정된 파일을 찾을 수 없습니다");
System.exit(0);
}
String name = prop.getProperty("name");
String[] data = prop.getProperty("data").split(",");
int max = 0, min = 0, sum = 0;
for(int i = 0; i < data.length;i++){
int intValue = Integer.valueOf(data[i]);
if(i ==0){
max = min = intValue;
}
if(max < intValue){
max = intValue;
}
else if(min > intValue){
min = intValue;
}
sum += sum += intValue;
}
System.out.println("이름 : " + name);
System.out.println("최대값 : " + max);
System.out.println("최소값 : " + min);
System.out.println("합계 : " + sum);
System.out.println("평균 : " + sum / data.length);
}
}XML파일, txt 생성을 작성해 보자
package CollectionFramework;
import java.util.*;
import java.io.*;
public class testing {
public static void main(String[] args){
Properties prop = new Properties();
// setProperty(String, String) : Properties에 Key-Value를 넣는다.
prop.setProperty("timeout","30");
prop.setProperty("language","한글");
prop.setProperty("size","10");
prop.setProperty("capacity","10");
// void store(Writer writer, String comments) : 저장된 목록을 Writer에 저장한다. comments는 목록에 대한 설명으로 저장된다.
// store(),storeToXML()는 IOException을 구현해야 사용할 수 있다. 그리고 FileOutputStream은 FileNotFoundException을 구현해야 사용할 수 있다.
// void storeToXML(OutputStream os, String comment) : 저장된 목록을 XML문서로 출력한다. comment는 목록에 대한 설명으로 저장된다.
try{
prop.store(new FileOutputStream("output.txt"), "Properties txt Example");
prop.storeToXML(new FileOutputStream("output.xml"), "Properties XML Example");
}catch (IOException e){
e.printStackTrace();
}
}
}
'Language > Java' 카테고리의 다른 글
| [Java] Maven설치하기(M1 mac) (0) | 2022.03.01 |
|---|---|
| [Java]제네릭스(Generics) (0) | 2022.02.16 |
| [Java] 컬렉션 프레임워크(Collection Framework) (0) | 2022.01.25 |
| [Java] 예외처리 (0) | 2022.01.08 |
| [Java]클래스간의 관계 결정하기 (0) | 2022.01.07 |
1. Collection Framework?
컬렉션 프레임웍이란 데이터군을 저장하는 클래스들을 표준화한 설계를 의미한다. 여기서 프레임웍이란 표준화된 프로그래밍 방식을 의미한다.
2. 컬렉션 프레임웍의 핵심 인터페이스
컬렉션 프레임웍의 핵심 인터페이스는 세가지가 존재한다.
- List : 순서가 있는 데이터 집합, 데이터 중복을 허용한다 (ArrayList, LinkedList, Vector, Stack)
- Set : 순서가 유지되지 않는 집합, 데이터 중복을 허용하지 않는다.(HashSet, TreeSet)
- Map : 키 - 값 쌍으로 이루어진 데이터 집합. 순서는 유지되지 않으며 키는 중복을 허용하지 않고, 값은 중복을 허용한다
주의할 것은 위 세가지 모두 '인터페이스'라는 것이다. 그리고 여기서 공통점이 많은 List, Set의 공통된 부분을 뽑아 Collection인터페이스를 재정의하였다. Map인터페이스는 공통점이없어 상속계층에도 포함되지 않는다.
3. Collection 인터페이스
List, Set의 조상인 Collection인터페이스에는 아래와 같은 메소드들이 있다.
- boolean add(Object o) : 지정 객체를 Collection에 추가
- void clear() : Collection내 객체를 모두 삭제
- boolean contains(Object o) : 지정된 객체가 컬렉션에 존재하는지 확인
- boolean containsAll(Collection c) : 지정된 컬렉션 내 객체들이 컬렉션에 있는지 확인
- boolean equals(Object o) : 동일한 컬렉션인지 확인
- int hashCode() : 컬렉션의 해시코드 반환
- boolean isEmpty() : 비어있는지 확인
- iterator iterator : 컬렉션의 iterator반환
- boolean remove(Object o) : 객체 o를 삭제
- boolean removeAll(Collection c) : 컬렉션에 포함된 객체를 삭제
- boolean retainAll(Collection c) : 지정된 Collection에 포함된 객체만 남기고 다른 객체들은 Collection에서 삭제한다
- int size() : 컬렉션에 저장된 객체 수 반환
- Object[] toArray() : 저장 객체를 객체배열로 반환
- Object[] toArray(Object[] a) : 지정된 배열에 컬렉션 객체를 저장해 반환
4. List인터페이스
List는 중복을 허용, 저장순서가 유지되는 컬렉션이다.
5. Set인터페이스
중복을 허용하지 않고, 저장순서가 유지되지 않는 컬렉션 클래스를 구현하는데 사용한다.
6. Map인터페이스
Map인터페이스는 키 - 값(Key : Value)를 하나의 쌍으로 묶어 저장하는 클래스이다.
7. Map.Entry인터페이스
Map인터페이스의 내부 인터페이스이다. Key-value쌍을 다루기 위해 내부적으로 구현해 놓았다. 내부 인터페이스인만큼 Map인터페이스를 구현하면 Map.Entry인터페이스도 같이 구현해야한다. 결론적으로 Entry는 (Key-Value)쌍을 의미한다.
- boolean equals(Object o) : 동일한 Entry인지 비교
- Object getKey() : Entry의 key객체를 반환한다
- Object getValue() : Entry의 value객체를 반환한다
- int hashCode() : 해시코드를 반환한다
- Object setValue(Object value) : Entry의 value객체를 지정된 객체(매개변수)로 바꾼다.
8. ArrayList
List인터페이스를 구현한 클래스이다. List를 구현한 만큼 저장순서가 유지되고 중복을 허용한다. 또한 기존에 있던 Vector를 개선한 클래스이다. Object배열을 이용해 데이터를 순차적으로 저장한다. 저장할 공간이 없으면 새로운 배열을 생성해 기존 배열에 저장된 내용을 배열로 복사 후 저장한다(System.arraycopy()원리)
package CollectionFramework;
import java.util.*;
public class testing {
public static void print(List l1, List l2){
System.out.println("List1 : " + l1);
System.out.println("List2 : " + l2);
}
public static void main(String[] args){
// Array List의 디폴트 크기는 10이다. 정수값을 넘겨 초기 크기를 정할 수 있다
ArrayList list1 = new ArrayList(16);
// boolean add(Object o) : ArrayList에 값을 넣는다
list1.add(new Integer(5));
list1.add(new Integer(3));
list1.add(new Integer(1));
list1.add(new Integer(2));
list1.add(new Integer(4));
// ArrayList(Collection c) : 주어진 컬렉션이 저장된 ArrayList생성
// List subList(int start, int end) : start ~ end - 1 index까지의 리스트반환
ArrayList list2 = new ArrayList(list1.subList(1,4));
print(list1,list2);
// Collections클래스 : collection을 활용할 수 있게 해주는 클래스
Collections.sort(list1); // Collections.sort() : 컬렉션을 정렬해준다
Collections.sort(list2);
//boolean containsAll(Collection c) : 컬렉션 c가 해당 컬렉션내 객체가 모두 포함되어있는지 반환
System.out.println("list1.containsAll(list2) : " + list1.containsAll(list2));
//List는 Object를 저장하므로, 모든 타입의 객체 저장 가능
list2.add("B");
list2.add("C");
print(list1,list2);
// add(int index, Object element) : 주어진 위치에 객체를 저장한다. 해당 위치에 이미 요소가 있다면 해당 요소부터 끝까지 한칸씩 뒤로 복사한다.
list2.add(3,"AA");
print(list1,list2);
// boolean retainAll(Collection c) : 지정된 Collection에 포함된 객체만 남기고 다른 객체들은 삭제
// list1에서 list2와 겹치는 부분만 남기고 나머지 삭제
System.out.println("list1.retainAll(list2) : " + list1.retainAll(list2));
print(list1,list2);
}
}ArrayList를 만들때는 여유있게 크기를 지정해 초기화 하는것이 좋다. 물론 공간이 부족하면 확장을 하지만, 배열을 복사하는 방식이므로 시간이 오래거린다.
9. LinkedList
배열은 가장 기본적인 형태의 자료구조로 구조가 간단하고 사용하기 쉽고, 데이터를 읽어오는데 걸리는 시간이 가장 빠르다는 장점이 있다.
- 크기를 변경할 수 없다
- 크기를 변경할 수 없으므로, 새로운 배열을 생성해서 데이터를 복사해야한다.
- 실행속도를 향상 시키기 위해서는 충분히 큰 크기의 배열을 생성해야 하므로 메모리가 낭비된다.
- 비순차적인 데이터의 추가 또는 삭제에 시간이 많이 걸린다.
- 차례대로 데이터를 추가하고 마지막에서부터 데이터를 삭제하는 것은 빠르다.
- 배열의 중간에 데이터를 추가하려면, 빈자리를 만들기 위해 다른 데이터들을 복사해서 이동해야한다.
배열의 단점을 보완하기 위해 링크드 리스트 라는 자료구조가 고안되었다. 링크드 리스트는 불연속적으로 존재하는 데이터를 서로 연결한 형태로 구성되어있다. 기본 링크드 리스트는 이동방향이 단방향이다. 다음 요소에 대한 접근은 쉽지만 이전 요소에 대한 접근은 어렵다 이를 보완한것이 더블링크드 리스트인데, 이는 양방향성으로 이동할 수 있다.
Java Linked List클래스는 더블 링크드 리스트로 구현되어있다. Linked List또한 List인터페이스를 구현했기 때문에 ArrayList와 메소드 종류, 기능은 거의 같다
package CollectionFramework;
import java.util.*;
public class testing {
public static void main(String[] args){
ArrayList al = new ArrayList(200000);
LinkedList ll = new LinkedList();
System.out.println("순차적으로 추가하기");
System.out.println("Array List : " + add1(al));
System.out.println("LinkedList : " + add1(ll));
System.out.println();
System.out.println("중간에 추가하기");
System.out.println("ArrayList : " + add2(al));
System.out.println("LinkedList : " + add2(ll));
System.out.println();
System.out.println("중간에서 삭제하기");
System.out.println("ArrayList : " + remove2(al));
System.out.println("LinkedList : " + remove2(ll));
System.out.println();
System.out.println("순차적으로 삭제하기");
System.out.println("ArrayList : " + remove1(al));
System.out.println("LinkedList : " + remove1(ll));
}
public static long add1(List list){
long start = System.currentTimeMillis();
for(int i = 0 ; i < 1000000;i++){
list.add(i+"");
}
long end = System.currentTimeMillis();
return end - start;
}
public static long add2(List list){
long start = System.currentTimeMillis();
for(int i = 0; i < 10000;i++){
list.add(500,"X"); // index 500번에 "X"라는 값을 계속 추가한다.
}
long end = System.currentTimeMillis();
return end - start;
}
public static long remove1(List list){
long start = System.currentTimeMillis();
for(int i = list.size() - 1; i >= 0; i--){
list.remove(i); // Object remove(int index) : index에 있는 값을 remove한다
}
long end = System.currentTimeMillis();
return end - start;
}
public static long remove2(List list){
long start = System.currentTimeMillis();
for(int i = 0; i < 10000;i++){
list.remove(i);
}
long end = System.currentTimeMillis();
return end - start;
}
}ArrayList와 LinkedList를 비교해본 코드이다.
순차적 추가 / 삭제같은 경우에는 ArrayList가 더 빠르다. 반면 중간 데이터를 추가 / 삭제하는 경우에는 LinkedList가 더 빠르다.
9. Stack과 Queue
Stack과 Queue에 대해 알아보자. 스택은 LIFO, 큐는 FIFO구조이다.스택같은 경우에는 데이터를 추가하고 삭제하는 방식이므로, ArrayList로 구현하는게 맞으며, Stack은 클래스가 구현되어있다. 큐는 ArrayList보다 데이터 추가 / 삭제가 쉬운 LinkedList가 더 효율적이다. Queue는 클래스ㅏ가 구현되어있지 않고, 인터페이스만 구현되어있다. Queue는 Queue를 구현한 클래스중 하나를 선택해 사용해야한다.
Stack의 메소드는 아래와 같은 것들이 있다.
- boolean empty() :Stack이 비어있는지 확인한다
- Object peek() : Stack의 맨 위에 저장된 객체를 반환한다. pop()과 달리 객체를 완전히 꺼내지 않는다.
- Object pop() : Stack의 맨 위에 저장된 객체를 꺼낸다
- Object push(Object item) : 스택에 객체를 저장한다
- int search(Object o) : Stack에서 주어진 객체를 찾아서 그 위치를 반환한다.
package CollectionFramework;
import java.util.*;
public class testing {
public static void main(String[] args){
Stack st = new Stack();
st.push("0");
st.push("1");
st.push("2");
System.out.println("Stack");
while(!st.empty()){
System.out.println(st.pop());
}
}
}Queue의 메소드는 아래와 같은 것들이 있다.
- boolean add(Object o) : 지정된 객체를 Queue에 추가한다
- Object remove() : Queue에서 객체를 꺼내 반환한다. 비어있는 경우 NoSuchElementException발생
- Object element() : 삭제없이 요소를 읽어온다. peek과 달리 Queue가 비어있을때 NoSuchElementException발생
- boolean offer(Object o) : Queue객체를 저장, 성공하면 true 실패하면 false를 반환
- Object poll() : Queue에서 객체를 꺼내서 반환, 비어있으면 null을 반환
- Object peek() : 삭제없이 요소를 읽어온다.Queue가 비어있으면 null을 반환
package CollectionFramework;
import java.util.*;
public class testing {
public static void main(String[] args){
Queue q = new LinkedList();
q.offer("0");
q.offer("1");
q.offer("2");
System.out.println("Queue");
while(!q.isEmpty()){
System.out.println(q.poll());
}
}
}https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/Queue.html
Queue (Java SE 17 & JDK 17)
Type Parameters: E - the type of elements held in this queue All Superinterfaces: Collection , Iterable All Known Subinterfaces: BlockingDeque , BlockingQueue , Deque , TransferQueue All Known Implementing Classes: AbstractQueue, ArrayBlockingQueue, ArrayD
docs.oracle.com
여기를 가면 Queue를 구현한 클래스들이 있다.(All known Implementing Classes)
10. Iterator, ListIterator,Enumeration
Iterator, ListIterator, Enumeration 은 모두 컬렉션에 저장된 요소를 접근하는데 사용되는 인터페이스이다. Enumeration은 Iterator의 구버전이며 , ListIterator는 Iterator의 기능을 향상시킨것이다.
< Iterator >
컬렉션 프레임웍은 저장된 요소들을 읽어오는 방법을 표준화했다. 각 요소에 접근하는 기능을 가진 iterator인터페이스를 정의하고, Collection인터페이스에는 Iterator를 반환하는 iterator()를 정의하고있다. iterator()는 Collection인터페이스에 정의된 메소드이다. 이는 당연하게도 자손 인터페이스인 List,Set에도 정의되어있다. iterator()로 Iterator를 얻은 후 요소를 읽을 수 있다. Iterator의 메소드는 아래와 같은 것들이 있다.
- boolean hasNext() : 읽어올 요소가 남아있는지 확인한다 있으면 true 없으면 false
- Object next() : 다음 요소를 읽어온다.
- void remove() : next()로 읽어온 후 삭제한다. 그렇기 때문에 next() 호출 후 호출해야한다.
아래와 같이 작성하면 코드 재사용성을 늘릴 수 있다.
package CollectionFramework;
import java.util.*;
public class testing {
public static void main(String[] args){
Collection c = new ArrayList();
for(int i = 0; i < 10; i++){
c.add(i + 1);
}
Iterator it = c.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}
ArrayList대신 Collection 타입으로 선언한 이유는 Collection이 List, Set계열 클래스들의 부모 클래스가 되기 때문이다. 그렇기 때문에 ArrayList가 아닌 LinkedList로 선언해도 사용이 가능한 것이다.(업캐스팅되는것이다)
< ListIterator >
ListIterator는 Iterator를 상속받아 기능을 추가한 것으로, 컬렉션의 요소에 접근할 때 Iterator는 단방향으로 이동할 수 있는 반면, ListIterator는 양방향 이동이 가능하다. 단 ListIterator는 List인터페이스를 구현한 컬렉션에서만 사용할 수 있다. ListIterator의 메소드는 아래와 같은 것들이 있다.
- void add(Object o) : 객체를 추가한다
- boolean hasNext() : 읽어올 요소가 남아있는지 확인한다
- boolean hasPrevious() : 읽어올 이전 요소가 있는지 확인한다
- Object next() : 다음 요소를 읽어온다.
- Object previous() : 이전 요소를 읽어온다
- int nextIndex() : 다음요소의 index를 반환한다
- int previousIndex() : 이전 요소의 index를 반환한다.
- void remove() : next혹은 previous로 읽어온 요소를 삭제한다
< Enumeration >
Enumeration은 Iterator의 구버전이라고 생각하면된다. 이전버전과의 호환성을위해 남겨두었으며 Iterator를 사용하는것이 좋다. 메소드는 아래와 같다
- boolean hasMoreElements() : 읽어올 요소가 남아있는지 확인한다. 있으면 true없으면 false를 반환한다 (Iterator의 hasNext)
- Object nextElement() : 다음요소를 읽어온다.(Iterator의 next)
11. HashSet
HashSet은 Set인터페이스 구현 클래스이다. Set인터페이스 특징대로 중복 요소를 저장할 수 없으며, 저장 순서도 유지되지 않는다. 저장순서 유지를 위해서는 LinkedHashSet을 사용해 주어야한다.
package CollectionFramework;
import java.util.*;
public class testing {
public static void main(String[] args){
Object[] objArr = {"1",new Integer(1),"2","2","2","3","3","4","4","4"};
Set set = new HashSet();
for(int i = 0; i < objArr.length; i++){
set.add(objArr[i]);
}
System.out.println(set);
}
}String 1과 Integer 1은 자료형이 다르기때문에 중복값으로 취급되지 않는다.
package CollectionFramework;
import java.util.*;
public class testing {
public static void main(String[] args){
Set set = new HashSet();
// int size() : 객체의 저장된 개수를 반환한다.
for(int i = 0; set.size() < 6;i++){
int num = (int)(Math.random() * 45) + 1;
set.add(new Integer(num));
}
// LinkedList(Collection c) : 컬렉션이 포함된 LinkedList를 반환한다.
List list = new LinkedList(set);
Collections.sort(list);
System.out.println(list);
}
}이번에는 객체를 Set에 넣어본다고 가정하자
package CollectionFramework;
import java.util.*;
class Person1{
String name;
int age;
Person1(String name, int age){
this.name = name;
this.age = age;
}
@Override
public String toString(){
return name + " : " + age;
}
}
public class testing {
public static void main(String[] args){
HashSet set = new HashSet();
set.add("abc");
set.add("abc");
set.add(new Person1("Hoplin",10));
set.add(new Person1("Hoplin",10));
System.out.println(set);
}
}
//Result : [abc, Hoplin : 10, Hoplin : 10]결과를 보면 Person1객체내 값이 겹치지만 중복값으로 인식하지 않는다. 이유는 HashSet같은 경우 새로운 요소 추가 전에 기존에 저장된 요소와 동일한 것인지 판별하기 위해서 equals()와 hashCode()를 호출하기 때문이다. 그렇기 때문에 equals()와 hashCode()를 오버라이딩 해서 구현해 주어야 한다.
package CollectionFramework;
import java.util.*;
class Person1{
String name;
int age;
Person1(String name, int age){
this.name = name;
this.age = age;
}
@Override
public String toString(){
return name + " : " + age;
}
@Override
public int hashCode(){
return (name + age).hashCode();
}
@Override
public boolean equals(Object obj){
if(obj instanceof Person1){
Person1 tmp = (Person1) obj;
return name.equals(tmp.name) && age == tmp.age; //name은 String 자료형이다. String 자료형은 내부적으로 equals와 hashCode는 값이 같은 경우 동일한 값으로 리턴하도록 되어있다.
}
return false;
}
}
public class testing {
public static void main(String[] args){
HashSet set = new HashSet();
set.add("abc");
set.add("abc");
set.add(new Person1("Hoplin",10));
set.add(new Person1("Hoplin",10));
System.out.println(set);
}
}
//Result : [abc, Hoplin : 10]equals는 Person1타입 객체인지 확인 후 name, age를 비교하는 방식으로 hashCode()는 name + age값(String)의 hashCode를 불러오는 방식으로 바꾸었다(String은 hashCode()메소드가 내용이 동일할 시에 같은 값으로 반환하도록 오버라이딩 되어있다). 단 아래 조건들을 만족해야한다
- 여러번 호출해도 동일한 int값을 반환해야한다
- equals메소드를 이용해 true를 얻은 두 객체에 대해 각각 hashCode()를 호출해 얻은 값은 같아야한다.
- equals를 이용해 false를 얻은 경우에는 hashCode()의 값이 같이도 괜찮지만 해싱을 사용하는 컬렉션 성능을 향상시키기 위해서는 다른 int를 반환하는것이 좋다.
12. HashMap과 Hashtable
HashMap은 Hashtable의 업그레이드 버전이다. HashMap은 키와 값을 묶어 하나의 데이터로 지정한다는 특징을 갖는다. 해싱을 사용하기 때문에 많은 양의 데이터를 검색하는데 있어서 뛰어난 성능을 보인다.
HashMap은 Entry라는 내부 클래스를 정의한다. 그리고 다시 Entry타입 배열을 선언한다. HashMap은 키와 값을 각각 Object타입으로 저장한다. 즉, (Object, Object)형태로 저장한다.
키는 저장된 값을 찾는데 이용되기 때문에 컬렉션 내에서 유일한 값이어야한다.
package CollectionFramework;
import java.util.*;
public class testing {
public static void main(String[] args){
HashMap map = new HashMap();
map.put("myID","1234"); // put(Object key, Object value) : Key - Value쌍을 맵에 넣는다
map.put("asdf","1111");
map.put("asdf","1234"); // 키값이 겹치는 경우에는 가장 나중에 들어오는 value의 값이 저장되게 된다
Scanner s = new Scanner(System.in);
while(true){
System.out.println("ID와 PW를 입력하세요.");
System.out.print("ID : ");
String id = s.nextLine().trim();
System.out.print("PW : ");
String pw = s.nextLine().trim();
System.out.println();
//boolean containsKey(Object key) : key값이 맵 내에 존재하는 확인한다.
if(!map.containsKey(id)){
System.out.println("입력하신 ID는 존재하지 않습니다. 다시입력해 주세요");
continue;
}
//Object get(Object key) : 지정된 Key의 값을 반환한다. 못찾으면 null반환
if(!(map.get(id)).equals(pw)){
System.out.println("비밀번호가 일치하지 않습니다. 다시입력해주세요");
}else{
System.out.println("id와 비밀번호가 일치합니다");
break;
}
}
}
}위 예제에서는 중복된 키값이 있기 때문에, 사실상 두개밖에 저장되지 않는다.
package CollectionFramework;
import java.util.*;
public class testing {
public static void main(String[] args){
HashMap map = new HashMap();
map.put("A",new Integer(100));
map.put("B",new Integer(200));
map.put("C",new Integer(300));
map.put("D",new Integer(80));
// Set entrySet() : HashMap에 저장된 키와 값을 엔트리의 형태로 Set에 저장해서 반환한다.
Set set = map.entrySet();
// Set은 iterator를 통해 값을 읽어올 수 있다.
Iterator it = set.iterator();
// Map.Entry : Key-Value를 다루기 위해 Map의 내부 인터페이스이다.
while(it.hasNext()){
Map.Entry e = (Map.Entry)it.next();
System.out.println("이름 : " + e.getKey() + "점수 : " + e.getValue());
}
// Set keySet() : HashMap에 저장된 모든 키가 저장된 Set을 반환한다.
set = map.keySet();
System.out.println("참가자 명단 : " + set);
// Collection values() : HashMap에 저장된 값들을 Collection형태로 반환한다.
Collection values = map.values();
it = values.iterator();
int total = 0;
while(!it.hasNext()){
Integer i = (Integer) it.next();
total += i.intValue();
}
System.out.println("총점 : " + total);
// int size() : map에 저장된 데이터 개수를 반환한다.
System.out.println("평균 : " + map.size());
// Collections.max : Collection에서 가장 큰 값을 반환한다
System.out.println("최고점수 : " + Collections.max(values));
// Collections.min : Collection에서 가장 작은 값을 반환한다
System.out.println("최저점수 : " + Collections.min(values));
}
}이번에는 중첩 HashMap을 사용해서 전화번호부를 만들어보자
package CollectionFramework;
import java.util.*;
public class testing {
static HashMap phoneBook = new HashMap();
public static void main(String[] args){
addPhoneNo("Friend","A","111111");
addPhoneNo("Friend","B","222222");
addPhoneNo("Friend","C","333333");
addPhoneNo("Company","D","777777");
addPhoneNo("Company","E","000000");
addPhoneNo("School","1234567");
printList();
}
static void addPhoneNo(String groupName,String name, String tell){
addGroup(groupName);
// Object get(Object key) : key값에 해당되는 value 값을 반환한다.
HashMap group = (HashMap) phoneBook.get(groupName);
// Object put(Object key, Object value) : map에 Key-Value쌍을 넣는다.
group.put(tell,name);
}
static void addPhoneNo(String name,String tell){
addPhoneNo("기타",name,tell);
}
static void addGroup(String groupName){
// boolean containsKey(Object key) : 키값이 있는지 확인한다.
if(!phoneBook.containsKey(groupName)){
phoneBook.put(groupName,new HashMap());
}
}
static void printList(){
// Map.Entry(Key-Value)타입의 쌍을 Set에 담아 반환
Set set = phoneBook.entrySet();
Iterator it = set.iterator();
while (it.hasNext()){
Map.Entry e = (Map.Entry)it.next();
// Map.Entry / Object getValue() : Entry의 Value값을 반환한다.
Set subset = ((HashMap)e.getValue()).entrySet();
Iterator subIt = subset.iterator();
// Map.Entry / getKey() : 키값 반환 | int size() : 저장된 데이터 개수 반환
System.out.println("* " + e.getKey() + "[" + subset.size() + "]");
while(subIt.hasNext()){
Map.Entry subE = (Map.Entry)subIt.next();
String telNo = (String) subE.getKey();
String name = (String) subE.getValue();
System.out.println(name + " " + telNo);
}
System.out.println();
}
}
}13. Properties
Properties는 HashMap의 구버전인 Hashtable을 상속받아 구현한 것으로 HashTable은 값을 (Object, Objcet)형태로 저장하는 반면 Properties는 (String, String)의 형태로 저장하는 더 단순화된 클래스이다. Properties는 주로 애플리케이션의 환경설정과 관련된 속성을 저장하는데 사용된다(XML, text파일 등). 그리고 데이터를 파일로부터 읽고 쓰는 편리한 기능을 제공한다. Properties 또한 Map인터페이스 구현체이므로 저장순서가 유지되지 않는다.
package CollectionFramework;
import java.util.*;
public class testing {
public static void main(String[] args){
Properties prop = new Properties();
// setProperty(String key, String value) : Key-Value를 저장한다 이미 존재하는 Key인 경우 value로 값이 대체된다.
prop.setProperty("timeout","30");
prop.setProperty("language","kr");
prop.setProperty("size","10");
prop.setProperty("capacity","10");
// Enumeration propertyNames() : Properties의 Key가 담긴 Enumeration을 반환한다.
Enumeration e = prop.propertyNames();
// Enumeration : hasMoreElements() : 불러올 값이 더 있는지 검사한다.
while(e.hasMoreElements()){
// Enumeration : nextElement() : 다음 값을 불러온다
String element = (String)e.nextElement();
// String getProperty(String key) : key에 대한 value값을 반환한다. Properties는 (String,String)이므로 String반환타입으로 되어있다.
System.out.println(element + "=" + prop.getProperty(element));
}
System.out.println();
prop.setProperty("size","20");
System.out.println("size = " + prop.getProperty("size"));
System.out.println("capacity = " + prop.getProperty("capacity","20"));
System.out.println(prop);
// void list(PrintStream out) : 지정된 PrintStream에 저장된 목록을 출력한다.
// System.out : 화면과 연결된 표준출력이다.
prop.list(System.out);
}
}텍스트 파일 변경하기 예제를 작성해보자.
package CollectionFramework;
import java.util.*;
import java.io.*;
public class prpty2 {
public static void main(String[] args){
if(args.length != 1){
System.out.println("USAGE : java prpty2 (filename)");
System.exit(0);
}
Properties prop = new Properties();
String inpFile = args[0];
try{
prop.load(new FileInputStream(inpFile));
}catch (IOException e){ // Properties.load의 예외
System.out.println("지정된 파일을 찾을 수 없습니다");
System.exit(0);
}
String name = prop.getProperty("name");
String[] data = prop.getProperty("data").split(",");
int max = 0, min = 0, sum = 0;
for(int i = 0; i < data.length;i++){
int intValue = Integer.valueOf(data[i]);
if(i ==0){
max = min = intValue;
}
if(max < intValue){
max = intValue;
}
else if(min > intValue){
min = intValue;
}
sum += sum += intValue;
}
System.out.println("이름 : " + name);
System.out.println("최대값 : " + max);
System.out.println("최소값 : " + min);
System.out.println("합계 : " + sum);
System.out.println("평균 : " + sum / data.length);
}
}XML파일, txt 생성을 작성해 보자
package CollectionFramework;
import java.util.*;
import java.io.*;
public class testing {
public static void main(String[] args){
Properties prop = new Properties();
// setProperty(String, String) : Properties에 Key-Value를 넣는다.
prop.setProperty("timeout","30");
prop.setProperty("language","한글");
prop.setProperty("size","10");
prop.setProperty("capacity","10");
// void store(Writer writer, String comments) : 저장된 목록을 Writer에 저장한다. comments는 목록에 대한 설명으로 저장된다.
// store(),storeToXML()는 IOException을 구현해야 사용할 수 있다. 그리고 FileOutputStream은 FileNotFoundException을 구현해야 사용할 수 있다.
// void storeToXML(OutputStream os, String comment) : 저장된 목록을 XML문서로 출력한다. comment는 목록에 대한 설명으로 저장된다.
try{
prop.store(new FileOutputStream("output.txt"), "Properties txt Example");
prop.storeToXML(new FileOutputStream("output.xml"), "Properties XML Example");
}catch (IOException e){
e.printStackTrace();
}
}
}
'Language > Java' 카테고리의 다른 글
| [Java] Maven설치하기(M1 mac) (0) | 2022.03.01 |
|---|---|
| [Java]제네릭스(Generics) (0) | 2022.02.16 |
| [Java] 컬렉션 프레임워크(Collection Framework) (0) | 2022.01.25 |
| [Java] 예외처리 (0) | 2022.01.08 |
| [Java]클래스간의 관계 결정하기 (0) | 2022.01.07 |